In the first article of my series From JavaScript developer to JavaScript engineer titled From JavaScript developer to JavaScript engineer: Re-implementing ECMAScript 2015’s String.prototype.repeat() method I’ve discussed how computer science concepts can help in writing better and more elegant software. Specifically, I’ve demonstrated how to use appropriate algorithms and data structures, together with techniques like memoization, to re-implement the String.prototype.repeat() method so that it’s blazing fast.
In this second article of the series, I’ll discuss how important is reasoning about the problem we’re facing. To do that, I’ll analyze the problem of finding all celebrities in a set of people.
If you want to take a look at the final solution, you can either go to the section An efficient solution or browse my Interview questions repository on GitHub.
Introducing the problem

The problem I’ll analyze in this article is about finding all the celebrities in a set of people. On its own, this isn’t very informative, so here it is the text of the problem:
A person is considered a celebrity if he/she likes nobody and everybody likes him/her. Given a set of people and a function
likes(i, j), which takes the names of two people as parameters and returnstrueif i likes j andfalseotherwise, write afindCelebrities()function to return all the celebrities in the given set.
The description of the problem might have still left you a bit confused, so let’s consider a couple of examples.
Given an empty set of people (for example, const people = [];), regardless of the values returned by the likes() function, findCelebrities() should return an empty set (that is []).
Let’s now consider a more complex example. Given a set of many people:
const people = [ 'Mark', 'David', 'John', 'Aurelio', 'Anna', 'Peter' ];
and the following likes() function:
function likes(i, j) {
return i !== 'Peter';
}
findCelebrities() should return:
findCelebrities(people, likes); // ['Peter']
These two examples have hopefully clarified the behavior of the findCelebrities() function. So, it’s now time to implement it.
A simple solution
The text of the problem asks to find all celebrities in a set of people. A celebrity is defined as someone that likes nobody and is liked by everyone. This condition can be expressed with the following set-builder notation:
![]()
This notation gives us the simplest solution to the problem. We start with a fixed person, let’s call this person candidate, and loop through the whole set P (where P stands for people) to verify the condition that everyone else likes candidate and candidate dislikes everyone else. We can stop the loop as soon as one of these two conditions is not verified. In such case, we know that candidate is not a celebrity. We then repeat this process for every person in the set P. Once done, we’ll obtain the set C of all the celebrities.
Turning this description into code, results in the following code:
function findCelebrities(people, likes) {
return people.filter(function(candidate) {
return !people.find(function(person) {
return person !== candidate &&
(likes(candidate, person) || !likes(person, candidate));
});
});
}
The code above is concise but not very efficient. If we analyze its time complexity, we can demonstrate that it’s an O(n2) where n is the number of the people in the set. The reason is that we loop over every person in the set and for each of them we scan again the whole set to verify that the conditions to be a celebrity are met.
If you have never heard of the Big O notation, I suggest you to learn more about it. It’s a fundamental concept to analyze the performance of your algorithms.
The time complexity of this function can be heavily improved. In the next section I’ll show you how.
Analysis of the problem
To understand how we can optimize findCelebrities(), we have to think what its weak points are.
Every set has at most one celebrity
The most important point to understand is the amount of celebrities that may be present in the given set. The text asks to find all of them, but in a given set there may be at most one. The demonstration can be made by using reductio ad absurdum.
Let’s say that more than one celebrity can be present in the set, for example two. We may assume, without loss of generality, that they are the first and the second person that we’ll process. Because the first person is a celebrity, it occurs that everyone else likes the person and the latter doesn’t like everyone else. But if this is true, then it means that the second celebrity is at least not liked by the first celebrity (it’s also true that the second celebrity likes someone, the first celebrity). Therefore, the second celebrity can’t be a celebrity at all, which confirms the previous statement.
Choosing the best candidate to be a celebrity
Thanks to the consideration of the previous section, we can optimize the algorithm to search for the best candidate to be a celebrity. Once we find it, we test that this person meets the two conditions required. If the conditions are met, we have a celebrity; otherwise the set doesn’t include any celebrity.
We can start with the assumption that the first person in the set is the best candidate and test the relation against the other people in the set, one at a time. If one of the two conditions is not met, that is if the candidate likes the person currently under analysis or the candidate isn’t liked by the person, we know that the current best candidate isn’t a celebrity. In particular, we deal with two possible scenarios:
- The current best candidate likes the person: without further processing, we assume the current person under analysis (the one the candidate was tested against) to be the best candidate and we continue the process
- The current best candidate doesn’t like the person but the latter doesn’t like the current best candidate: both of them are not celebrities. Therefore, we can continue the process starting from the person following the one we tested against
On the other hand, if both the conditions are met while analyzing a candidate and a person, we can exclude the latter as a celebrity. In fact, because both the conditions are met, it means that the person likes the candidate and the person isn’t liked by the candidate.
Once we complete this process, we test that our best candidate meets the two conditions against all the other people in the set (those that haven’t been tested yet with this candidate).
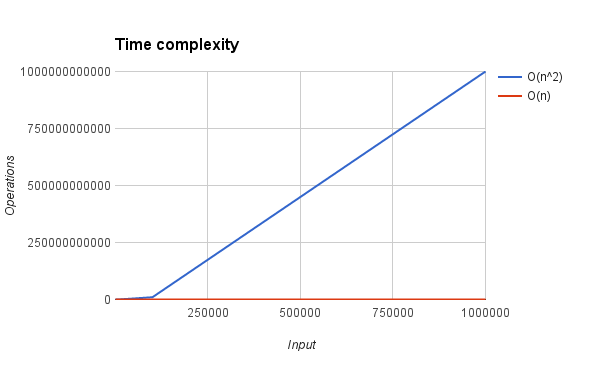
This new approach changes the time complexity of the function. We have passed from an execution time that can be expressed by a squared function to an execution time that can be expressed by a linear function. So, if our set was made of 1000 people, we have moved from 1000000 operations to just 1000 operations. The image below should also help in visualizing the difference in the operations executed by the two versions discussed in this post.
New approach in action
To further clarify the strategy described, let’s discuss an example with the support of some images. Let’s say that we have a set of people defined as follows:
const people = [ 'Mark', 'David', 'John', 'Aurelio', 'Anna', 'Peter' ];
The likes() function for this example is reported below:
function likes(i, j) {
const likesMap = new Map([
['Mark', ['David', 'John', 'Aurelio', 'Anna', 'Peter']],
['David', ['Mark', 'Anna', 'Peter']],
['John', ['Mark', 'David', 'Aurelio', 'Anna']],
['Aurelio', ['Peter', 'Anna']],
['Anna', []],
['Peter', ['Anna']]
]);
return likesMap.get(i).includes(j);
}
Let’s now see what happens by applying the approach discussed in this section.
Step 1
We assume the best candidate to be the first element in the set, Mark. We start to scan the set from the person at the second position (having index of 1), David.
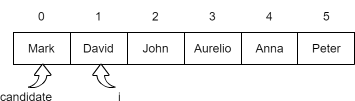
The call to likes('Mark', 'David') returns true, so Mark can’t be a celebrity. We update our candidate variable, and we set it so that the new potential celebrity is David. We continue to loop over the set.
Step 2
Our candidate is David and we test him against John.

The call to likes('David', 'John') returns false. To know if we have to keep David as the best candidate, we need to test if John likes David. The call to likes('John', 'David') returns true. So, at least for now, David is a good candidate to be a celebrity. But we have many other people to test against, so we continue to loop over the set.
Step 3
We test David against Aurelio.

The call to likes('David', 'Aurelio') returns false. Unfortunately, the call to likes('Aurelio', 'David') returns false as well, hence David can’t be a celebrity. Moreover, because Aurelio is not liked by at least one person (David), we can exclude Aurelio too.
We update the candidate variable so that the new potential celebrity is Anna. This time we also update i to have as a value the index of the person following Anna in the set (Peter).
Step 4
The new candidate is Anna and we test her against Peter.

The call to likes('Anna', 'Peter') returns false and the call likes('Peter', 'Anna') returns true. This means that Anna is still a good candidate to be a celebrity.
Peter is the last person in the set, so we keep Anna as the best candidate and we move onto the next part of the process.
Step 5
We have verified that both the conditions to be a celebrity are met for all the people that come after Anna in the set. So, now we need to test that the conditions are verified for all the people that come before Anna. If all the tests are passed, Anna is a celebrity; if even one condition is not met, there are no celebrities in the set and we can stop searching for one.
Without showing the steps left, I can assure you that Anna will be successfully verified as a celebrity.
With this last consideration, we are ready to implement the final solution. If you want to see some metrics about how the first solution and the efficient solution compares, have a look at the section titled Performance comparison.
An efficient solution
Thanks to our analysis of the problem, we’re now ready to implement an efficient version of the findCelebrities() function.
We can start by managing the cases where the set of people is either empty or contains only one person. In these cases, the celebrities are zero and one respectively.
if (people.length < 2) {
return people.slice();
}
If the set of people contains more than one person, we can start the process outlined in the section Choosing the best candidate to be a celebrity. So, we start assuming our best candidate to be a celebrity is the first person in the set. Then, we test the candidate against all of the other people. Along the way, we might need to update the best candidate because we find that the current one likes someone or the candidate isn’t liked by someone.
let candidate = 0;
for (let i = 1; i < people.length; i++) {
if (likes(people[candidate], people[i])) {
candidate = i;
} else if (!likes(people[i], people[candidate])) {
candidate = ++i;
}
}
When testing the best candidate against the last person in the set, we might find out that both of them aren’t celebrities. In this case, candidate will be updated to an index outside of the range of the set. If this happens, we know that the set doesn’t include any celebrity.
if (candidate === people.length) {
return [];
}
Finally, we verify that the conditions to be a celebrity are met against all the people that haven’t been tested in the previous scan. If any of the conditions is not met, we return an empty set; otherwise we return a set that contains as its only element the best candidate.
for (let i = 0; i < candidate; i++) {
if (likes(people[candidate], people[i]) ||
!likes(people[i], people[candidate])
) {
return [];
}
}
return people.slice(candidate, candidate + 1);
The final version of the findCelebrities() function can be found in my Interview questions repository on GitHub and it’s also listed below:
function findCelebrities(people, likes) {
if (people.length < 2) {
return people.slice();
}
let candidate = 0;
for (let i = 1; i < people.length; i++) {
if (likes(people[candidate], people[i])) {
candidate = i;
} else if (!likes(people[i], people[candidate])) {
candidate = ++i;
}
}
if (candidate === people.length) {
return [];
}
for (let i = 0; i < candidate; i++) {
if (likes(people[candidate], people[i]) ||
!likes(people[i], people[candidate])
) {
return [];
}
}
return people.slice(candidate, candidate + 1);
}
Performance comparison
Now that we’ve discussed the simple and the final version, it’s worth discussing how faster the latter improves the performance compared to the former. In this section, I want to show you some data so that you can visualize the improvement.
The table below shows the number of operations of the two versions for different sizes of the set of people.
| Size | Simple | Final |
|---|---|---|
| 1 | 1 | 1 |
| 10 | 100 | 10 |
| 100 | 10000 | 100 |
| 1000 | 1000000 | 1000 |
| 10000 | 100000000 | 10000 |
| 100000 | 10000000000 | 100000 |
The second table reports the execution times of both the solutions. To calculate them, I used the High Resolution Time API to retrieve the current time in milliseconds, with the microseconds in the fractional part. Moreover, in order to have a more accurate estimation, I’ve executed both the functions for 10000 times and calculated the average execution time for each value of size. It’s also important to mention the conditions in which the functions were executed. The set of people was always created to include a celebrity and to have it in the middle. So, if the size of the set was 1000, the celebrity was at position 500.
| Size | Simple | Final |
|---|---|---|
| 1 | 0.0013237499999999482 | 0.002664349999999955 |
| 10 | 0.004032200000000131 | 0.0013155000000000467 |
| 100 | 0.10371665000000113 | 0.0016612499999999995 |
| 1000 | 9.445168000000002 | 0.008824599999999932 |
| 10000 | 888.4801000000001 | 0.10347660000000054 |
| 100000 | 94304.16500000001 | 1.0804022500000032 |
As you can see, the difference in performance of the two functions is astonishing. For a set of people of size 100000, the final version is ~87200 times faster than the simple version.
Conclusions
In this second article of my series From JavaScript developer to JavaScript engineer, I’ve discussed the problem of finding all the celebrities in a set. The main take-away lesson of this article is that reasoning about the problem we’re facing is very important because it allows us to avoid sub-optimal solutions and it might lead us to conclusions we didn’t foresee at the beginning. The findings of our analysis can help us in writing better and faster software.